
DeepSeek即将发布R2??坊间传闻越来越多了,且难辨真假。
1.2T万亿参数,5.2PB训练数据,高效利用华为芯片……只能说如果有一半是真的都很牛了。


HuggingFace创始人此时推荐“以不变应万变”,打开官方认证账号的更新提醒,就能第一时间获取通知。
抛开具体泄露数据是否准确,大家似乎有一个共识:如果真的有R2,它的基础模型会是新版DeepSeek V3-0324。
之所以有很多人相信R2会在4月底发布,有一部分原因也是出于R1与V3之间相隔了一个月左右。
现在,等不及DeepSeek官方,开源社区已经开始自己动手给V3-0324加入深度思考了。

新模型DeepSeek-R1T-Chimera,能力与原版R1相当,但速度更快,输出token减少40%,也是基于MIT协议开放权重。
相当于拥有接近R1的能力和接近V3-0324的速度,结合了两者的优点。
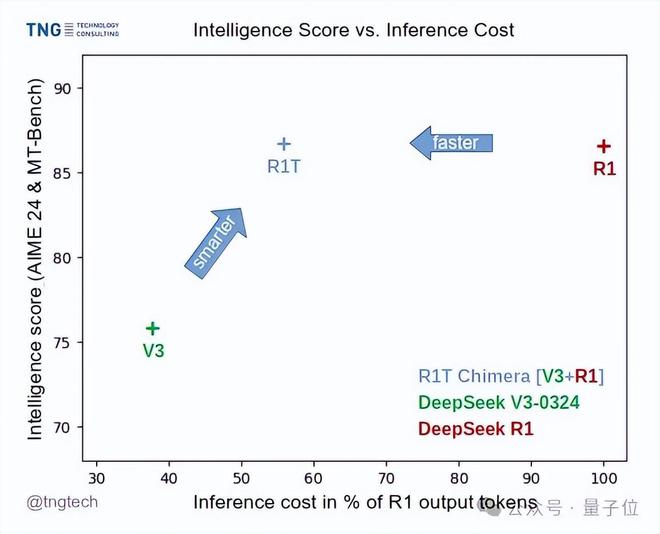
而且做到这一点,不是靠微调或蒸馏,而是DeepSeek V3-0324和R1两个模型融合而成。
R1+V3融合模型
新模型R1T-Chimera并非DeepSeek官方出品,而是来自德国团队TNG Technology Consulting。

该团队此前也探索过可调专家混合(MoTE)方法, 让DeepSeek-R1在推理部署时可以改变行为。

新的R1T-Chimera模型权重可在HuggingFace下载,也可以在OpenRouter免费在线试玩。
目前已知是选用了V3-0324的共享专家+R1与V3-0324的路由专家的混合体融合而来。

TNG团队表示最终结果令人惊讶,不仅没有表现出融合模型的缺陷,相反,思考过程还比原版R1更紧凑有序。

暂没有技术报告或更详细的模型融合方法公布,要验证它是否符合描述,就只能拉出来试一试了。
我们选用最新折磨AI的难题“7米长的甘蔗如何通过2米高1米宽的门?”。
原版R1思考了13秒就下了结论;R1T Chimera在这里却足足思考了101秒,最终计算出可以通过。
虽然还是无法像人类一样直观的理解三维空间,让甘蔗与门的平面垂直就可通过,但依然通过计算夹角与投影得出了结论。
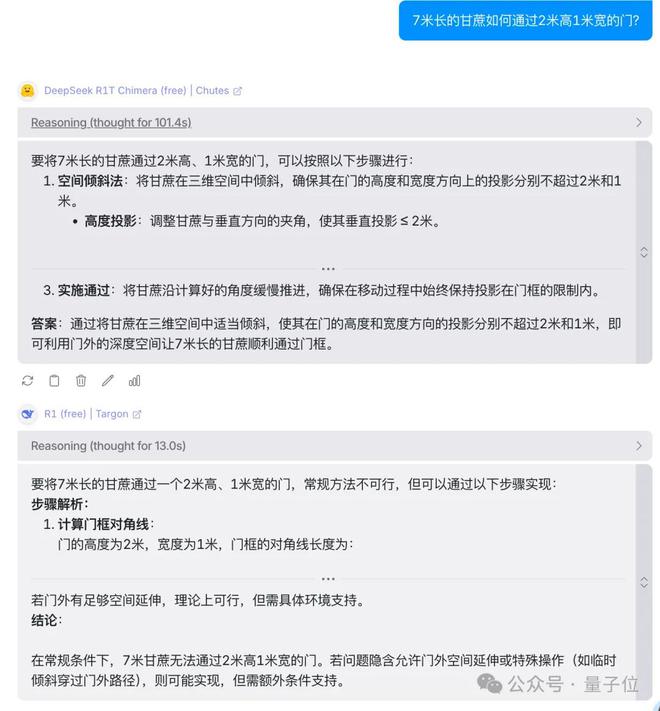
在这100秒时间里R1T-Chimera如何一步步思考出答案呢?
展开推理token可以发现,在简单计算二维方案不可行后,它就已经想到了三维方案。

后面依然陷入了各种误区,在旋转甘蔗、弯曲甘蔗、计算“门的厚度”上走了弯路。

最终通过“揣摩出题人心理”走进正确的路线。
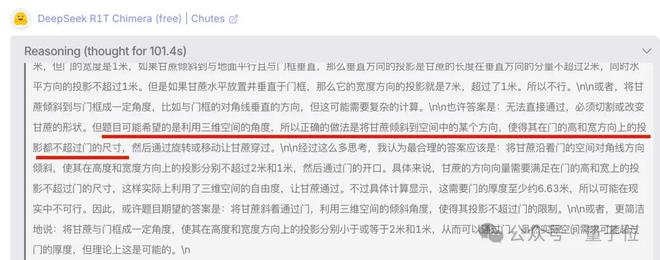
最终给出的答案非常严谨了。
虽然人类直觉上就能想出把甘蔗垂直起来通过这个方法,但仔细一想,题目中确实没有给出“门后有多少空间这个条件”。

细还是AI细。
关于R1T-Chimera的更多细节,大家还在等TNG团队消息和更多第三方基准测试结果。

不过也有人注意到,KIMI K1.5技术报告中也探索了模型融合方法。
具体来说是把长思维链(long-cot)模型和短思维链(short-cot)模型融合,直接对两个模型的权重取平均值,获得一个新模型,无需重新训练。

不过在实验中,这种简单融合方法表现并不如这篇论文中提出的Long2short强化学习方法。
另一个在模型融合上有经验的团队是Transformer作者Llion Jones创办的Sakana AI。
早在24年初就结合进化算法提出以block为单位融合的方法。

随着更多团队跟进这一路线,模型融合会不会成为2025年大模型的一大技术趋势呢?欢迎在评论区留下你的看法。
HuggingFace:
https://huggingface.co/tngtech/DeepSeek-R1T-Chimera
在线试玩:
https://openrouter.ai/tngtech/deepseek-r1t-chimera:free
参考链接:
[1]https://x.com/tngtech/status/1916284566127444468
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/9568.html