
微软以小搏大,发布首个开源2B参数规模“原生1bit”LLM——
BitNet b1.58 2B4T,单CPU就能跑,性能与同规模全精度开源模型相当。
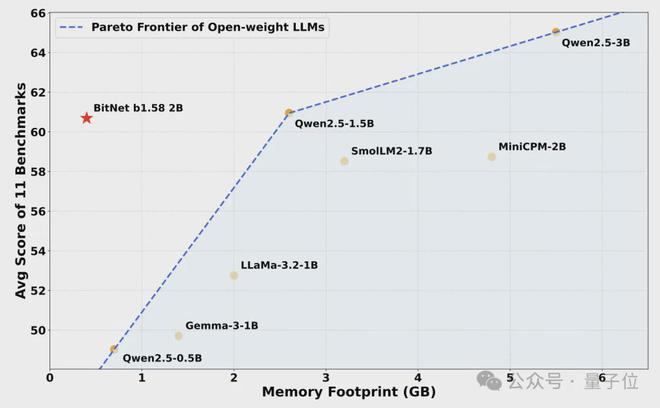

它采用三进制{-1, 0, 1}存储权重,相较于传统的16位浮点数可大幅降低显存需求。
只需0.4GB内存即可运行。
基于4T token语料训练,BitNet b1.58 2B4T在保持性能的同时,计算效率突出。
单个CPU即可达到“与人类阅读速度”相当的速度,每秒5-7个token,CPU端解码延迟29ms,能耗低至0.028J。
这种效率使其可在普通笔记本电脑甚至边缘设备上实时运行。
例如在苹果M2 CPU上快速运行:

另外值得一提的是,BitNet b1.58 2B4T具有原生训练优势,与训练后量化(PTQ)模型对比,避免了PTQ常见的性能衰减
BitNet b1.58 2B4T刚发布就吸引了大量网友点赞关注,作者们也当起了自己个儿的自来水。
如何实现原生1bit?话不多说,一起来看看技术详情。
权重映射为三元值{-1, 0, +1}
BitNet b1.58 2B4T模型基于Transformer架构,对核心组件进行了系统性改造。
传统LLM依赖16bit或32bit浮点数存储权重,而BitNet b1.58 2B4T采用一种称为absmean的量化方案,将权重映射为三元值{-1, 0, +1},平均每个权重仅需1.58bit(log₂3≈1.58)来表示。
模型内存占用骤降至0.4GB,仅为同类全精度模型的1/5-1/12。
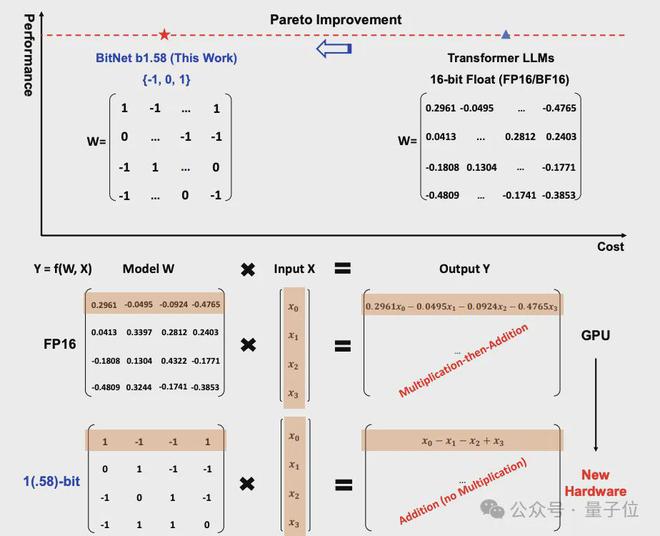
另外,线性投影中的激活值被量化为8bit整数,采用基于每token的absmax量化策略,团队还引入subln归一化,增强量化训练稳定性。
其它关键设计包括:
- 激活函数:前馈网络(FFN)子层采用ReLU²替代常见的SwiGLU,通过提升模型稀疏性,优化了1bit环境下的计算特性。
- 位置编码:使用旋转位置嵌入(RoPE)。
- 偏置消除:与Llama等架构一致,所有线性层和归一化层均移除偏置项,减少参数量并简化量化流程。
训练方面,BitNet b1.58 2B4T采用三阶段训练:大规模预训练监督微调(SFT)和直接偏好优化(DPO)。
先是大规模预训练,模型经历了两阶段学习率调度:得益于1bit模型的训练稳定性,初期采用高学习率快速收敛;中期骤降至低水平,使模型能在高质量数据上精细化调整。配合动态权重衰减策略,模型在保持泛化能力的同时避免过拟合。
监督微调(SFT)阶段,值得注意的是,训练中采用损失函数求和而非平均策略,并延长了训练轮次,这一调整被证明对低精度模型的收敛至关重要。
直接偏好优化(DPO)阶段,基于UltraFeedback、MagPie等人类偏好数据集,模型通过无奖励模型的直接优化,提升了回答的安全性与用户满意度,避免了传统RLHF的高计算成本。
实验效果方面,BitNet b1.58 2B4T内存占用仅为0.4GB,CPU端解码延迟29ms,能耗低至0.028J。
在数学推理任务GSM8K中,BitNet以58.38的准确率远超Llama 3.2-1B(38.21)和Qwen2.5-1.5B(56.79);在常识推理任务WinoGrande中,BitNet 71.90的得分超同类模型均值(63.55)。
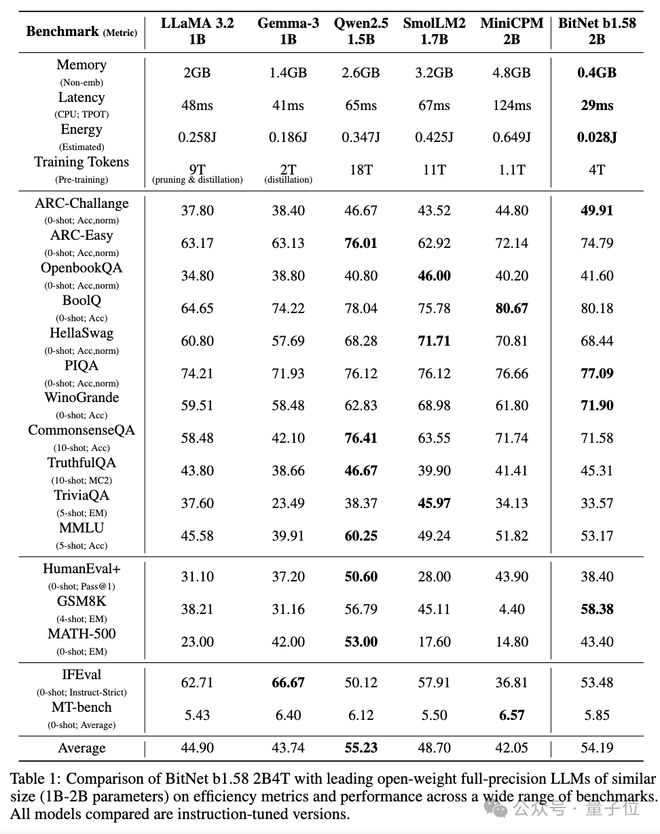
团队特别指出,BitNet b1.58 2B4T具有原生训练优势。与训练后量化(PTQ)模型对比,BitNet的原生1bit训练策略避免了PTQ常见的性能衰减。
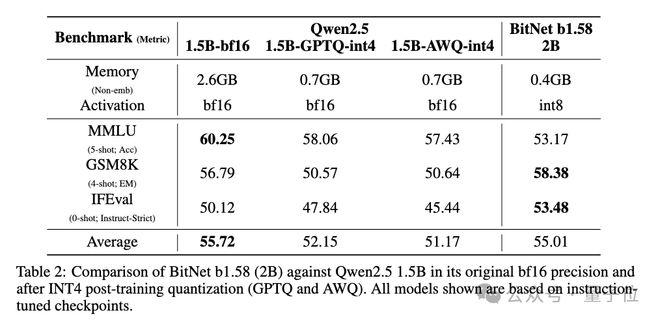
参数更大的Llama3-8B模型量化至1bit后,也难打BitNet b1.58 2B4T。
和其它1bit模型相比,BitNet b1.58 2B4T也有显着更强的整体性能,绝大多数基准测试中取得SOTA。
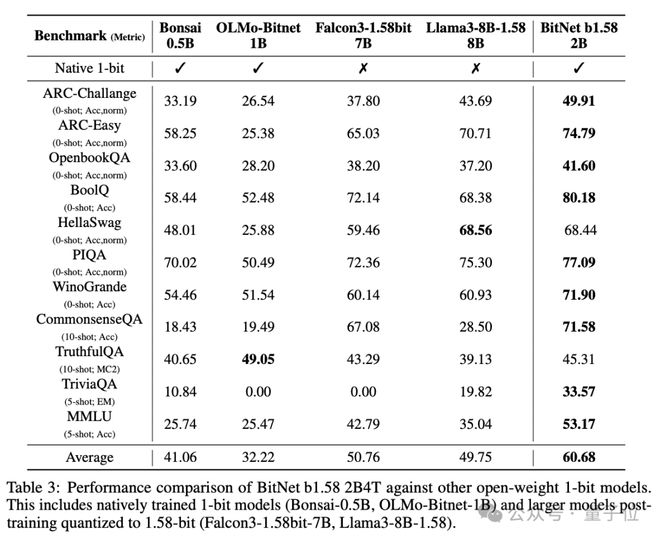
有关BitNet b1.58 2B4T的具体表现,再来看几个例子。
让它生成几个笑话,笑话简短但也蛮有意思:

单CPU生成97个token,总耗时3.452秒,每秒处理 28.1 token。
再让它基于2000年的背景,让一位PowerPC处理器爱好者和一位英特尔处理器爱好者进行五行辩论。
BitNet b1.58 2B4T生成结果也很快,并且反映了那个时代科技行业的竞争特性。

微软在1 bit LLM上的探索
1 bit LLM的实现方法,微软其实早在2023年就有相关研究,当时就称为BitNet,用BitLinear替换了nn.Linear

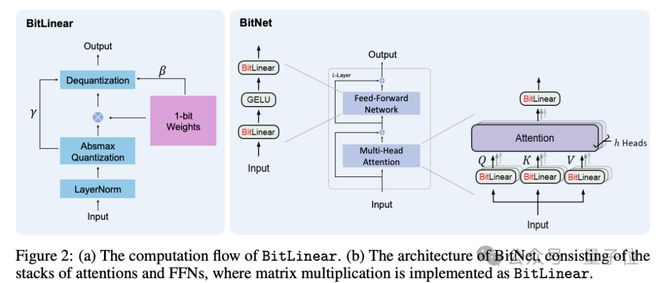
之后,微软原班人马在上一篇论文的基础之上做了优化,提出BitNet b1.58,在原始BitNet的基础上增加了一个额外的0值
也就是“The Era of 1-bit LLMs”这篇论文,用6页研究引发网友广泛关注。

这种方法发布后,也有不少人在这项研究的基础之上进行探索。Huggingface Transformers还曾整合了BitNet b1.58,运用一些技巧,使得现有模型可以直接微调到1.58bit。
接着,微软还开发并开源了针对GPU和CPU平台的专用推理库
BitNet b1.58采用独特量化方案(1.58bit权重和8bit激活值,W1.58A8)需要专门的实现,标准深度学习库通常缺乏针对这种混合精度、低比特格式的优化内核,微软开发了专门针对W1.58A8矩阵乘法的自定义CUDA内核。
另外,微软还开源了bitnet.cpp——一个用于1 bit LLM CPU推理的官方参考C++库,提供针对标准CPU架构优化的内核,旨在高效适配模型的特定量化方案,尽可能避免通用量化库的开销或复杂的底层位操作。
技术报告:https://arxiv.org/abs/2504.12285
抱抱脸链接:https://huggingface.co/microsoft/bitnet-b1.58-2B-4T
参考链接:https://arstechnica.com/ai/2025/04/microsoft-researchers-create-super%e2%80%91efficient-ai-that-uses-up-to-96-less-energy/
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/7169.html