
多模态生成技术持续突破内容创作的边界。
生数作为多模态领域的明星玩家,所提供的技术正推动AI视频创作进入系统性可用新阶段。
在本次第三届AIGC产业峰会上,生数科技产品副总裁、Vidu产品负责人廖谦分享了这样的观点:


为了完整体现廖谦的思考,在不改变原意的基础上,量子位对演讲内容进行了编辑整理,希望能给你带来更多启发。
中国AIGC产业峰会是由量子位主办的AI领域前沿峰会,20余位产业代表与会讨论。线下参会观众超千人,线上直播观众320万+,累计曝光2000万+。
话题要点
- 视频生成进入黄金发展期,将迎来“Midjourney V5时刻”级别的突破。
- AI能够给专业创作者、C端消费者和B端企业客户都带来生产力的加持。
- 大模型的可控生成问题亟待解决和突破。
- 多模态大模型一定会诞生出新的内容平台。
以下为廖谦演讲全文:
多模态大模型的终局:诞生新的内容平台
多模态大模型可以简单分为两个方向:第一是多模态的理解,第二是多模态的生成。
今天我的分享主要聚焦在多模态的生成这一方向。
首先看整体的技术发展,从最左边的曲线看,主要是文本生成这一块,也就是大语言模型。文本生成的工作起步相对更早一些,随着GPT系列技术不断的演进,它的技术范式相对来说确立一些。
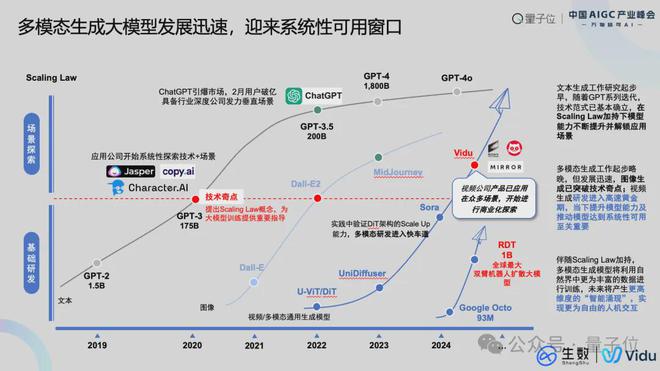
在Scaling Law的加持下,这块发展得非常快,解锁的应用场景非常多。而多模态的起步相对晚一些,中间这条曲线是图像生成,图像生成已经突破了技术的基点,不管是Midjourney,还有很火的GPT-4o吉卜力的风格在网络上有非常多的流传,这一块发展速度非常快。
第三条曲线是视频生成,现在视频生成的研发进入到黄金发展期,当下如何去提升模型的能力、从而达到系统性可用,是我们要去重点解决的问题。
除了视频生成,最近还有一个很重要的方向是具身智能,具身智能也是多模态方向的应用。当多模态的模型可以利用更多维度的数据,不仅仅局限于文本,还包含音频、视频,甚至包括感觉类信息的时候,我相信会产生更高维度的智能涌现。
在产品方面,从2024年Sora发布首个宣传片,到2024年4月生数科技发布了Vidu——中国首个长时长、高动态性、高一致性的视频大模型。从去年9月开始,产品的迭代速度非常快,大家都是以月、甚至是周的维度在进行应用的更新、模型的进展。
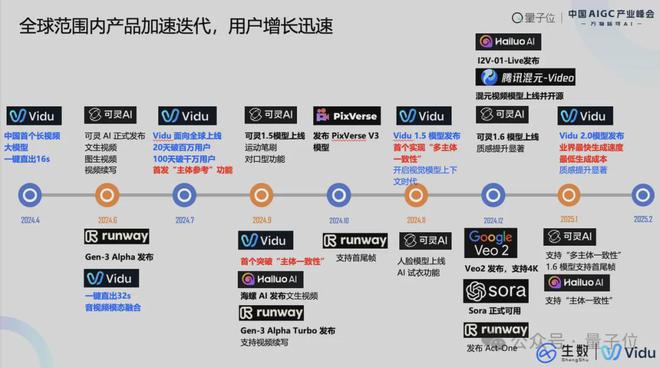
多模态生成,尤其是视频生成领域,到底有哪些场景和应用的落地?
这里也分享一些Vidu在全球的落地实践。去年《毒液:最后一舞》在中国上映的时候,就是用Vidu制作的中国宣传片,这也是好莱坞五大电影公司首次在中国拥抱AI。
像这样的内容,完全是由AI生成的。如果用传统的方式去做,一般需要超过30天,但当时我们总共只花了10天时间。AI除了降本,还可以增效、释放无尽想象力。这个影片里的转场特效,其实给创作者带来了很大的启发。
此外,我们的超创艺术家柔树特效还一个人制作了动漫作品,他利用了非常多的AI工具、AI生图、AI生音乐,包括利用我们的Vidu去做AI的视频生成。这样的内容过去一个人完成是不可能的,当前多模态大模型技术不断发展,已经让一人工作室成为了可能。现在业界已经有了非常多的小团队、甚至个人也能进行高质量的内容制作。
AI除了给专业创作者带来了一些生产力的加持,对我们大众、对我们C端消费者也带来了深远的影响。
这是我们在大众娱乐全球用户的使用场景。从去年8月份开始,社交媒体上兴起了非常大的一股AI特效玩法的浪潮,包括前几天GPT4o也属于这样的范畴。
去年的时候我们看到全球社交媒体上有非常多AI拥抱、AI亲吻,甚至一些变身的玩法,尤其是我们发现很多用户可以跟去世的亲人或者明星进行互动。多模态技术发展之前,这样的内容制作成本非常高,也不可能说仅仅上传张两张图片就能达到这样的效果。
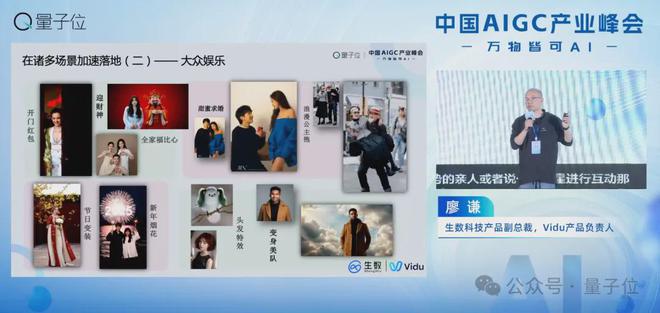
除了大众娱乐和专业创作者,我们在广告营销、内容营销领域也有非常多的落地实践。
第一个是电商的场景,电商我们有非常多的存量的营销图片,在视频的时代,不管亚马逊电商或者其他电商,都会希望商家上传尽可能多的视频内容,基于存量图片我们可以结合大模型生成一些内容,包括人物、物体的运镜转场,还有比较趣味的动态海报,用户所需要的仅仅是上传一些图片加上提示词描述即可。
然而,多模态生成还是有很多问题亟待解决,其中一个重要的问题就是如何解决随机的问题,让模型按照我们想要的方式生成。
实际上生数科技自成立以来一直在研究和思考可控生成问题。
第一个可控问题是位置,上面是输入图片,我们可以拟定一些角色、场景和道具的参考,也希望模型按照我们画的线稿图确定位置。

当前的行业现状是,它的物理规律和出现的方式非常奇怪,很难做到可控。但是在Q1模型的加持下,我们可以做到精准控制不同角色的位置,也能做到比较符合人类的审美和自然规律。
除了位置可控,还有运动布局的可控。给定人物角色、场景和道具,我们希望按照我们想要的轨迹进行运动。行业现状是虽然我们给了一些参考,但是出现的方式很奇怪。而未来ViduQ1模型可以精准控制机器人,从画外走向画内,比例和轨迹运动的幅度都会比较自然。

生数科技将于下周发布Vidu Q1模型,欢迎大家届时在APP端和网页端体验。Q1的更多可控相关功能未来也会陆续上线,敬请期待。
我们这次会推出可控音频,通过文字加上时间轴的方式控制音频的生成,我们只需要输入下面的文字就可以生成对应的音频,整体做到视频和音频同时精准的控制。
我相信今年是多模态生成的爆发之年,在多模态领域我认为有三个方面趋势:
- 趋势一,视频生成这一块内容大量大幅提升,将迎来视频生成领域的Midjourney V5时刻。
- 趋势二,当前视频生成主要是默剧片断的方式,并不是音视频内容的直接生成,今年大模型会发展成音视频直接生成的情况。
- 趋势三,我们相信有非常多专业和半专业用户会涌入,之前还在犹豫观望的人群将大规模涌入产生破圈高价值的内容。

作为产品经理,我也分享一下对多模态大模型终局的思考。
我认为多模态大模型一定会诞生出新的内容平台,这个内容平台跟当前的内容平台肯定不一样。当前内容平台不管是TikTok或者YouTube,更多内容是提前制作好的,不管内容是UGC(用户生成内容)或者PGC(专业生产内容),通过推荐算法做到内容的个性化推荐,但它并不是内容的个性化生成。
随着多模态技术发展,当多模态可以做到实时可控、可交互的时候,它可以是完全个性化的,届时一定会诞生出带来新体验的内容平台,这个技术未来将应用在社交、游戏、VR、AR等多个领域,会对所有的行业带来非常深远的影响。
关于生数科技
生数科技成立于2023年3月,创始人是朱军教授,致力于打造全球领先的多模态大模型及应用产品,该团队在国际顶会和顶刊上发表的论文超30篇。
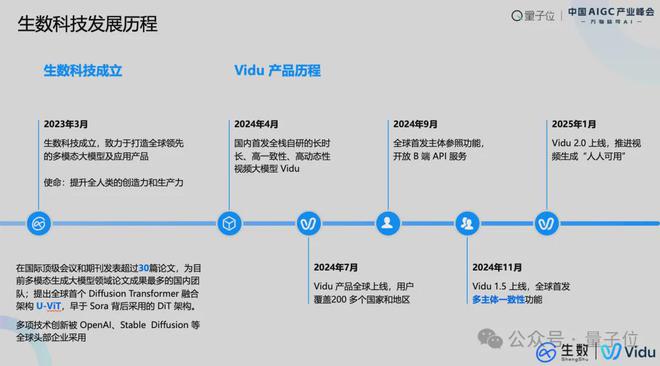
目前,生数科技在全球取得了一些成绩,当前已经支持面向全球海量用户和企业用户。
ToC方面,Vidu产品上线20天用户突破百万,上线100天突破千万用户,且用户绝大部分来自于海外;ToB方面,生数科技也跟国内外的一些巨头和创业公司有合作,包括百度、360、美图、同花顺等。
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/6472.html