
就在刚刚,智谱一口气上线并开源了三大类最新的GLM模型:
- 沉思模型GLM-Z1-Rumination
- 推理模型GLM-Z1-Air
- 基座模型GLM-4-Air-0414
若是以模型大小(9B和32B)来划分,更是可以细分为六款。


首先是两个9B大小的模型:
- GLM-4-9B-0414:主攻对话,序列长度介于32K到128K之间
- GLM-Z1-9B-0414:主攻推理,序列长度介于32K到128K之间
还有四个32B大小的模型,它们分别是:
- GLM-4-32B-Base-0414:基座模型,序列长度介于32K到128K之间
- GLM-4-32B-0414:主攻对话,序列长度介于32K到128K之间
- GLM-Z1-32B-0414:主攻推理,序列长度介于32K到128K之间
- GLM-Z1-32B-Rumination-0414:主攻推理,序列长度为128K
而随着一系列模型的开源,智谱也解锁了一项行业之最——
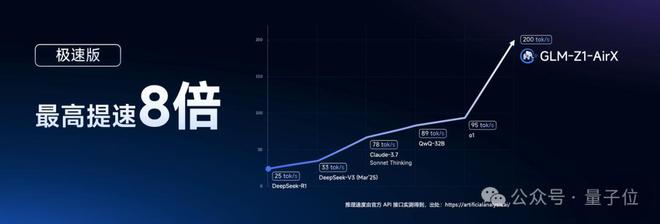
推理模型GLM-Z1-32B-0414做到了性能与DeepSeek-R1等顶尖模型相媲美的同时,实测推理速度可达200 tokens/秒。
如此速度,已然是目前国内商业模型中速度最快,而且它的高性价比版本价格也仅为DeepSeek-R1的1/30。
值得一提的是,本次开源的所有模型均采用宽松的MIT许可协议。
这就意味着上述的所有模型都可以免费用于商业用途、自由分发,为开发者提供了极大的使用和开发自由度。
那么这些开源模型的效果又如何?
(PS:文末有彩蛋~)
先看性能
首先来看下GLM-4-32B-0414。
它是一款拥有320亿参数的基座大模型,其性能足以比肩国内外规模更大的主流模型。
据了解,这个模型基于15T高质量数据进行预训练,其中特别融入了大量推理类合成数据,为后续强化学习扩展提供了坚实基础。
在后训练阶段,智谱团队不仅完成了对话场景的人类偏好对齐,还运用拒绝采样和强化学习等先进技术,重点提升了模型在指令理解、工程代码生成、函数调用等关键任务上的能力,从而显着增强了智能体执行任务的核心素质。
实际测试表明,GLM-4-32B-0414在工程代码编写、Artifacts生成、函数调用、搜索问答及报告撰写等多个应用场景均展现出色表现。
部分基准测试指标已达到或超越 GPT-4o、DeepSeek-V3-0324(671B)等更大规模模型的水平。

从实测效果来看,GLM-4-32B-0414进一步提升了代码生成能力,可处理并生成结构更复杂的单文件代码。
例如来上这么一段Prompt:
再如:
以及设计一个小游戏也是不在话下:

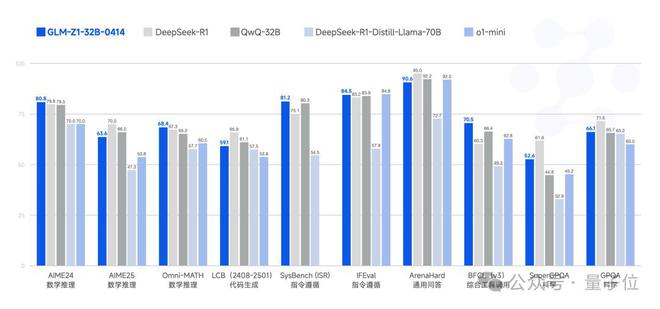
再来看下GLM-Z1-32B-0414的性能,一款专为深度推理优化的模型。
这个模型在GLM-4-32B-0414的基础上,采用了冷启动结合扩展强化学习的策略,并针对数学推导、代码生成、逻辑推理等高难度任务进行了专项优化,显着提升了复杂问题的解决能力。
此外,它还通过引入基于对战排序反馈的通用强化学习(RLHF),模型的泛化能力得到进一步强化。
尽管仅拥有32B参数,GLM-Z1-32B-0414在部分任务上的表现已可媲美 671B 参数的DeepSeek-R1。
在AIME 24/25、LiveCodeBench、GPQA等权威基准测试中,该模型展现出卓越的数理推理能力,能够高效应对更广泛、更具挑战性的复杂任务。
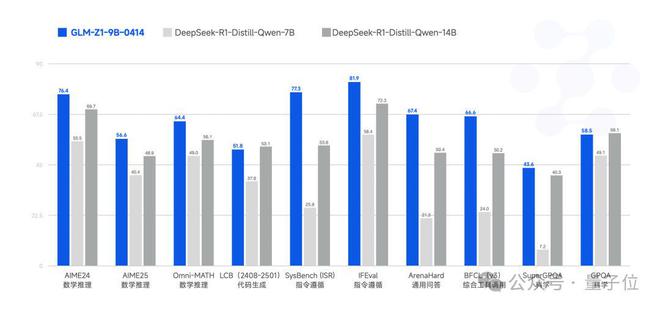
接下来,是更小规模的GLM-Z1-9B-0414,在技术上是沿用了上述模型的方法。
虽然只有9B大小,但它在数学推理及通用任务上展现出超越参数规模的卓越性能,综合表现稳居同量级开源模型前列。
尤其值得关注的是,在资源受限的应用场景中,该模型能够高效平衡计算效率与推理质量,为轻量化AI部署提供了极具竞争力的解决方案。
最后,再来看下沉思模型GLM-Z1-Rumination-32B-0414。
这个模型可以说是智谱对AGI未来形态的一个探索。
沉思模型采用与传统推理模型截然不同的工作范式,通过多步深度思考机制有效应对高度开放性和复杂性问题。
其核心突破体现在三个方面:
- 在深度推理过程中智能调用搜索工具处理复杂子任务;
- 创新性地引入多维度规则奖励体系,实现端到端强化学习的精准引导与扩展;
- 完整支持”问题发现→信息检索→逻辑分析→任务解决”的研究闭环系统。
这些技术创新使该模型在学术写作、深度研究等需要复杂认知能力的任务上展现出显着优势。
例如让它回答一个科学假设推演问题:
再看价格
除模型开源外,基座、推理两类模型也已同步上线智谱MaaS开放平台(bigmodel.cn),面向企业与开发者提供API服务。
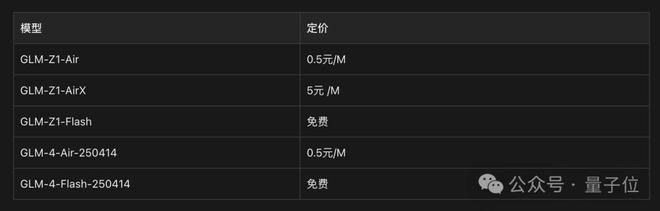
本次上线的基座模型提供两个版本:GLM-4-Air-250414和GLM-4-Flash-250414,其中GLM-4-Flash-250414完全免费。
上线的推理模型分为三个版本,分别满足不同场景需求:
- GLM-Z1-AirX(极速版):定位国内最快推理模型,推理速度可达 200 tokens/秒,比常规快 8 倍;
- GLM-Z1-Air(高性价比版):价格仅为 DeepSeek-R1 的 1/30,适合高频调用场景;
- GLM-Z1-Flash(免费版):支持免费使用,旨在进一步降低模型使用门槛。
为了更加一目了然,价格表如下:
至于配置方面,32B基础模型、32B推理模型、32B沉思模型(裸模型)的要求如下:
- 1张H100 / A100或者更先进的NVIDIA旗舰显卡
- 4张4090/5090/3090
One More Thing
除了上述内容之外,智谱这次还有一个亮点的动作——
拿下一个顶级域名Z.ai!
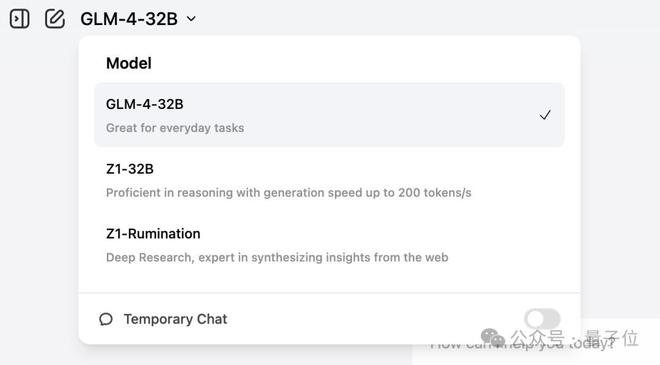
目前已经上线了下面三款模型:
而且官方还亮出了一个比较有意思的slogan:

最后,纵观智谱在大模型时代的发展,不得不感慨其更新迭代以及开源的速度。
这样难怪它能成为第一家正式启动IPO流程的“大模型六小龙”。
体验地址:
z.ai
主题测试文章,只做测试使用。发布者:人脑网,转转请注明出处:https://www.rennao.com.cn/5763.html